源码茶舍之没有epoll就没有Handler
Handler,英文释义:处理者,处理程序。他就是Android系统中的打工人,背负着传递消息的重任。很多人在第一次尝试去阅读framework源码时,可能也是从Handler消息机制开始的,我们会发现源码的很多地方都用到了Handler。然而,他好像并没有我们想象的那么简单,如果我们要深入探索的话,可以一直追溯到Linux内核。
预备
本文分析源码均基于API 29,来源于官方AOSP:cs.android.com
问号
Handler的API使用还是比较简单的,我们比较常用的就是通过类似如下方式来发送一个Runnable到Handler所在线程去执行:
1 | new Handler().post(() -> { /* do something */ }); |
这里为了简单直接用了匿名类,当然你也可以实现自定义的Handler并重写 handleMessage 方法来处理消息。post 最终其实还是调用到了Handler的 sendMessageDelayed 方法,将Runnable封装成一个Message发送到消息队列MessageQueue中,最后再由Looper循环将其取出,再交回Handler来处理。因此我们在子线程调用主线程的Handler来发送消息时,就达到了异步执行任务再将结果告知主线程的目的。
好奇的同学就会有问号了,这个上面的delay延迟执行是如何实现的(今天的重点)?是定时器吗?还是周期性轮询?还是事件驱动?带着这些疑问,就不得不深入源码了。
Java层
废话不多说直接看Handler源码:
1 | public final boolean sendMessageDelayed( Message msg, long delayMillis) { |
这里有个细节,最终调用的是 sendMessageAtTime 方法,且并没有直接把delay时长传进去,而是通过加当前时间得到一个确切时间作为参数传递的。这样做的原因:后续调用到系统底层时,若再需要这个delay,会用这个确切的uptime减去新的当前时间,保证精准,减少误差(因为从应用层调用到底层还是需要不少时间的)。
Handler的 enqueueMessage 方法稍作处理后会调用到MessageQueue的同名方法,在分析之前我们大脑中先保留一个粗浅的概念以便于理解后面的源码,就是当消息队列为空或者队头的消息delay时间还没到时,相关代码阻塞(但线程释放CPU资源进入休眠状态),新的消息来时才可能唤醒,后面我们会剖析其原理。说回来,先看MessageQueue的 enqueueMessage :
1 | boolean enqueueMessage(Message msg, long when) { // when就是上面的uptimeMillis |
这段代码比较简单,主要就是把新来的消息按delay时间排序入队,并在必要情况下进行唤醒操作。产生的疑问便是:
- 这个唤醒是唤醒了个什么?为什么要进行native方法调用?
- 传进来的when时间字段赋值给msg了,后续又如何利用的呢?
带着这些问题,我们就要去找Looper了,因为它是整个消息机制流水线的发动机,其动力在 loop 方法:
1 | public static void loop() { |
原来Looper这个家伙很懒啊,直接调用了queue的 next 方法,并没有单独去处理消息delay时间的问题。结果还是MessageQueue最累。当然,Looper本身的职责也不是这些,它做好消息的分发就行了。
来看MQ的 next 方法,马上我们就要进入仙境了:
1 | Message next() { |
从上述可见,我们一开始传进来的delay延时,经过一路波折,来到了 nativePollOnce(ptr, nextPollTimeoutMillis) 本地方法,此方法是阻塞调用,再结合前面的 nativeWake(ptr) 方法,我们可以对消息机制的延时原理有一个初步认知:
- 当通过
postDelayed发送延时消息后,传入的时间最终会通过nativePollOnce方法进行带超时的阻塞,以达到延时的目的,时间到后阻塞结束,next方法再返回消息对象给Looper。 - 在MessageQueue的
enqueueMessage方法中会判断新插入的消息的时间是否小于队头消息的时间,以决定要不要立即唤醒,即通过nativeWake方法打断超时未到的阻塞。
Java层分析到此其实差不多了,但是好奇的同学自然又会思考这个阻塞不会一直占用CPU资源吗?难道这就是Android耗电的真凶!?如果这么想的话,那你还是低估了Linux。为了进一步搞清楚这个Native阻塞,我们就要深入到Android系统的Native源码了。
Native层
按照源码的规范,我们可以直接找到MessageQueue的cpp代码:frameworks/base/core/jni/android_os_MessageQueue.cpp 中的 nativePollOnce 函数:
1 | static void android_os_MessageQueue_nativePollOnce(JNIEnv* env, jobject obj, |
进一步找到 system/core/libutils/Looper.cpp 的 pollOnce:
1 | int Looper::pollOnce(int timeoutMillis, int* outFd, int* outEvents, void** outData) { |
pollInner 代码很长,但其实核心就是 epoll_wait 这个系统调用,我们先大概看看它的函数定义(epoll_wait(2) — Linux manual page , Epoll-wiki),后文再详解:
1 | int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout); |
epoll_wait这里也是整个Android消息机制阻塞的真正位置,阻塞等待期间可以保证线程进入休眠状态,不占用CPU资源,同时监听所注册的事件。
简单地讲,就是等待注册在文件描述符 epfd 上的事件,等事件产生的时候,传入的events数组会被填充,以便于epoll_wait返回后处理事件,也就是我们上面源码中 for (int i = 0; i < eventCount; i++) 干的事情。所以这个epoll应该是一个事件驱动的机制。
为什么不着急讲上面的 awoken() 函数,因为在此之前,我们必须基本了解Linux的文件描述符(fd)、管道(pipe)和epoll机制,有了这些预备知识我们就能明白一切了。
内核知识简介
文件描述符(File Descriptor)
以下部分简称FD。摘录维基百科的概念:
计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。
概念看起来有点抽象,在理解FD之前我们需要感悟Linux的设计思想:一切皆文件。“Linux中一切都可以看作文件,包括普通文件、链接文件、Socket以及设备驱动等,对其进行相关操作时,都可能会创建对应的文件描述符。文件描述符是内核为了高效管理已被打开的文件所创建的索引,用于指代被打开的文件,对文件所有I/O操作相关的系统调用(例如read、write等)都需要通过文件描述符。”
可见,在Linux中,FD就是一种宝贵的系统资源,就像工业时代的石油一样,没有它,我们的文件系统就无法运转。本质上,一个Linux进程启动后,会在内核空间生成文件描述符表(FD Table),记录当前进程所有可用的FD,也即映射着该进程所有打开的文件,这里引用一张其他大佬的图,就更形象了:
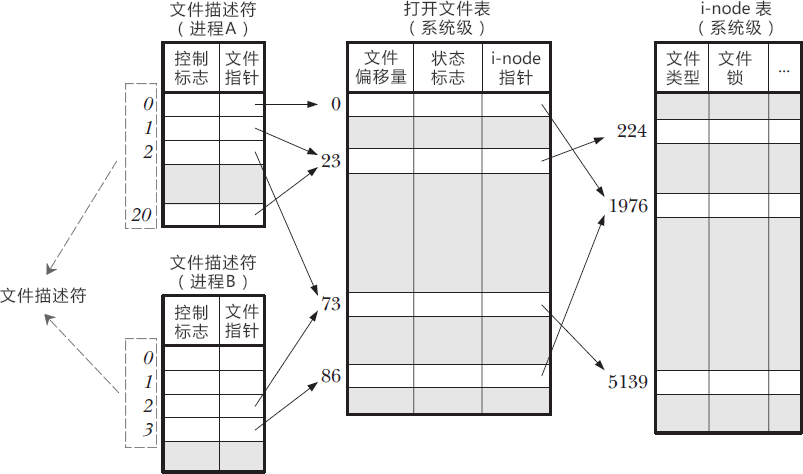
FD实际上就是文件描述符表的数组下标(所以是非负整数)。通俗地总结就是系统操作I/O资源的钥匙。更多细节大家可自行查阅或参考文末链接,此处点到为止。
我们由此还可以萌生一个初步概念:有了方便的文件操作,我们就能实现跨进程通信了。
管道(pipe)
那么什么又是管道呢?同样地,我们先看看百科的概念:
在类Unix操作系统(以及一些其他借用了这个设计的操作系统,如Windows)中,管道(英语:Pipeline)是一系列将标准输入输出链接起来的进程,其中每一个进程的输出被直接作为下一个进程的输入。
这个概念是由道格拉斯·麦克罗伊为Unix命令行发明的,因与物理上的管道相似而得名。
这个概念还算比较形象,管道就是通常用于进程间通信的一种机制。如其名,就像水管的一端输水,另一端接水。pipe的发明人发现系统操作执行命令的时候,经常有需求要将一个程序的输出交给另一个程序进行处理,这种操作可以使用输入输出配合文件来实现,比如:
1 | ls > abc.txt # 把当前目录的文件列表输入到abc文本 |
这确实很麻烦,管道的出现简化了这个操作,现在我们可以用管道符(通常这么称呼)竖线来连接两个命令:
1 | ls | grep xxx |
达到同样的效果,还不需要显式地产生文件。shell会用一个管道连接两个进程的输入输出,以此实现跨进程通信。因此,我们可以把管道的本质理解成一个文件,前一个进程用写的方式打开文件,后一个进程用读的方式打开。所以管道的系统调用函数是这样的:
1 | int pipe(int pipefd[2]); |
函数调用后会创建2个文件描述符,即填充pipefd数组,其中pipefd[0]是读方式打开,pipefd[1]是写方式打开,分别作为管道的读和写描述符。管道虽然形式上是文件,但本身并不占用磁盘存储空间,而是占用的内存空间,所以管道是一个操作方式和文件相同的内存缓冲区(所以我们也不用狭隘地理解Linux中的文件,并非存在磁盘上的才叫文件)。写入管道的数据会被缓存到直到另一端读取为止,所以上述命令是阻塞的,在ls没有结果产生之前grep并不会执行。
所以在实践中,我们通常让一个进程关闭读端,另一个进程关闭写端,以实现单工通信,引用一张其他大佬的图:
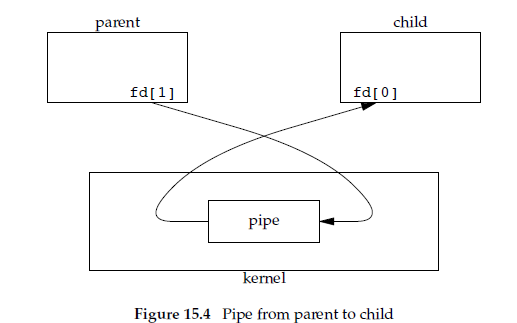
类似这样的代码,了解其形式即可(更多细节可以参考文末链接):
1 | // 父进程fork产生子进程后 |
此外,我们必须清楚的是,pipe并不只能用于跨进程通信,在同一个进程内当然也是可用的。
epoll
了解文件描述符和管道后,我们终于可以讲epoll机制了。依然先看定义:
epoll是Linux内核的可扩展I/O事件通知机制。于Linux 2.5.44首度登场,它设计目的旨在取代既有POSIX select(2)与poll(2)系统函数,让需要大量操作文件描述符的程序得以发挥更优异的性能。epoll 实现的功能与 poll 类似,都是监听多个文件描述符上的事件。
epoll 通过使用红黑树(RB-tree)搜索被监控的文件描述符(file descriptor)。在 epoll 实例上注册事件时,epoll 会将该事件添加到 epoll 实例的红黑树上并注册一个回调函数,当事件发生时会将事件添加到就绪链表中。
说明epoll是一种I/O事件通知机制(事件驱动的,犹如观察者模式)。我们上文提到管道机制,需要一端写数据另一端才能读数据,但在实践中,我们往往不能这样无尽地等待,而是希望有一个监听,你什么时候写再通知我去读。
在epoll出现之前,也有诸如select和poll这样的监听机制,但是效率比较低,有些需要无差别遍历FD,虽然也是非阻塞,但唤醒后要轮询I/O,或者是有FD监听数量上限等缺点,具体此处不赘述。
总之,epoll解决了这些问题,实现了高性能的I/O多路复用,还使用mmap加速内核与用户空间的消息传递。epoll的系统调用也比较简单,就3个函数:
1 | // 在内核中创建epoll实例并返回一个epoll文件描述符 |
epoll内部实现还是比较复杂的,用红黑树结构管理fd,双向链表结构管理回调的事件,具体可以参考文末链接。简单的讲一下原理,epoll_ctl 函数会把传入的fd和event进行存储,并与相应的设备驱动程序建立关系,当相应的事件发生时,就会调用内部的回调函数将事件添加到链表中,最终通知线程唤醒,epoll_wait 得以返回。没有事件发生时,epoll_wait 就是挂起状态。
这里注意不要混淆了:epfd是epoll程序实例的描述符或者说索引;fd是与你想要监听的事件所对应的描述符,最终读写管道依赖的也是这个fd。
回溯Native层
终于搞清楚了epoll,我们再回去看MessageQueue和Looper的Native源码,就非常清晰了。
还记得我们上文MQ中的mPtr变量吗,实际上在MQ的构造方法中进行了初始化:
1 | MessageQueue(boolean quitAllowed) { |
所以在Native层也有一个MQ对象,mPtr是MQ在Native层的一个映射引用,方便上层寻址访问:
1 | static jlong android_os_MessageQueue_nativeInit(JNIEnv* env, jclass clazz) { |
再看看Looper的初始化过程:
1 | Looper::Looper(bool allowNonCallbacks) |
此时我们再回过头去看Looper的 pollInner 函数,epoll_create1 、 epoll_ctl 、 epoll_wait 这三个epoll流程就这样联系了起来:
1 | int Looper::pollInner(int timeoutMillis) { |
可见,awoken (被唤醒的意思)函数实际上就是一个管道的读操作,既然此时被epoll事件驱动唤醒起来读,那么肯定就是监听到对应的写操作导致的,显然,写操作就在 wake 函数中:
1 | void Looper::wake() { |
这里需要额外提醒一下,旧版本的源码是这样创建唤醒事件描述符的:
1 | int wakeFds[2]; |
读和写是两个描述符,而最新的系统源码中只用了一个mWakeEventFd描述符,可能是考虑到Handler消息机制并不需要跨进程的缘故,具体还有待研究。
上述的 Looper::wake() 函数源头其实就是是由MQ的 nativeWake 函数调用的:
1 | static void android_os_MessageQueue_nativeWake(JNIEnv* env, jclass clazz, jlong ptr) { |
回想一下上文,nativeWake(mPtr); 在Java层就是由 enqueueMessage 方法调用的,即消息入队时。至此,我们终于贯通了整个流程,从Java层一直探索到了Linux内核的系统调用,喜大普奔啊!
总结一下,回到标题,为什么说没有epoll就没有Handler。因为Handler + Looper + MessageQueue这一套消息机制之所以可以处理延时消息,且达到事件驱动的效果,还不占用CPU资源,究其本质就是Native层使用了Linux内核的epoll I/O事件通知机制。满足了两个场景:
当通过
postDelayed发送延时消息后,传入的时间最终会通过nativePollOnce方法进行带超时的阻塞,本质上是因为epoll_wait函数的挂起,达到了延时的目的。时间到后阻塞结束,
epoll_wait返回,线程被重新唤醒并获得CPU资源,且epoll事件数(event_count)为0,说明中途没被唤醒,然后nativePollOnce直接返回,进而MQ的next方法再返回消息对象给上层Looper。在MessageQueue的
enqueueMessage方法中会判断新插入的消息的时间是否小于队头消息的时间,以决定要不要立即唤醒,即通过nativeWake方法打断超时未到的阻塞。若需唤醒,便会往wake pipe唤醒管道中写入数据(其实就是一个整数1),由于epoll监听了mWakeEventFd唤醒事件描述符,所以此时
epoll_wait结束了挂起状态,返回事件数大于0,进而调用到awoken,最后nativePollOnce返回result为POLL_WAKE,上层消息得以继续处理。因为我们知道Looper的loop是一直在循环调用next的,如果底层不醒,上层就会阻塞。
所以要么是timeout到了自动唤醒,要么是由于新消息插入导致主动唤醒。用不太严谨的流程图来描述一下主动唤醒的过程:
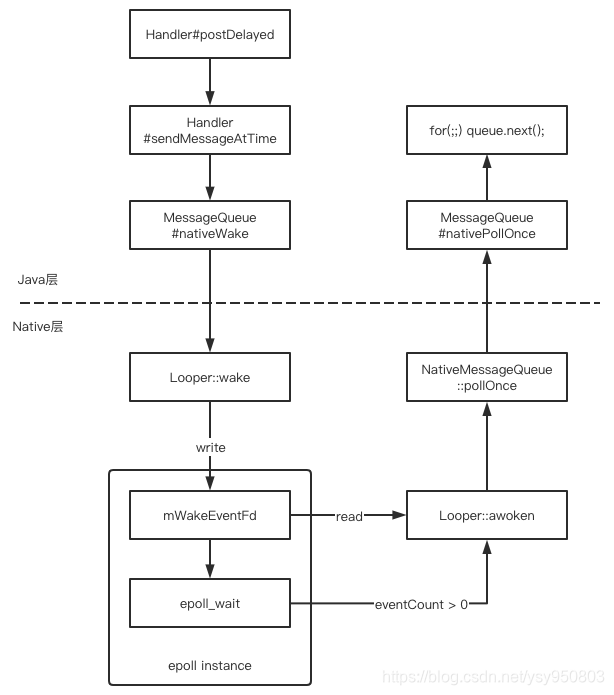
后话
在应用进程退到后台时,一般情况下就没有什么消息发送了,所以主线程便阻塞在queue.next()中的 nativePollOnce 方法里,并释放CPU资源进入休眠状态,并不会消耗大量CPU资源。即便在前台,只要你的UI没有动画绘制或者没有触摸交互,也是差不多的状态。这也回答了为什么Looper中在进行无限循环却不会导致异常耗电的问题。
关于Linux系统调用为什么可以挂起且不占用CPU时间片,CPU的定时器和中断又是怎么实现的?那可能就涉及到硬件知识了,好好复习组成原理吧哈哈哈。后续有空我也会补充上来。
其实研究到最后,我才悟出了为什么epoll要叫epoll,因为它和原来poll机制的最大区别就是改善成了event(事件)驱动,这个e如果我没猜错的话应该代表的就是event。
参考
 支付宝(移动端可点击二维码)
支付宝(移动端可点击二维码) 微信(仅支持扫码)
微信(仅支持扫码) PayPal (QR Code Clickable)
PayPal (QR Code Clickable) Others (QR Code Clickable)
Others (QR Code Clickable)

